


PacktPub 50 Hours of Big Data, PySpark, AWS, Scala, and Scraping Video

PacktPub: 50 Hours of Big Data, PySpark, AWS, Scala, and Scraping (Video)
ISBN 9781803237039 | Course Length 54 hours 32 minutes | 17 GB
ISBN 9781803237039 | Course Length 54 hours 32 minutes | 17 GB
PacktPub 50 Hours of Big Data, PySpark, AWS, Scala, and Scraping Video
PacktPub 50 Hours of Big Data, PySpark, AWS, Scala, and Scraping Video
PacktPub 50 Hours of Big Data, PySpark, AWS, Scala, and Scraping Video
PacktPub 50 Hours of Big Data, PySpark, AWS, Scala, and Scraping Video
Part 1 is designed to reflect the most in-demand Scala skills. It provides an in-depth understanding of core Scala concepts. We will wrap up with a discussion on Map Reduce and ETL pipelines using Spark from AWS S3 to AWS RDS (includes six mini-projects and one Scala Spark project).
Part 2 covers PySpark to perform data analysis. You will explore Spark RDDs, Dataframes, a bit of Spark SQL queries, transformations, and actions that can be performed on the data using Spark RDDs and dataframes, the ecosystem of Spark and Hadoop, and their underlying architecture. You will also learn how we can leverage AWS storage, databases, computations, and how Spark can communicate with different AWS services.
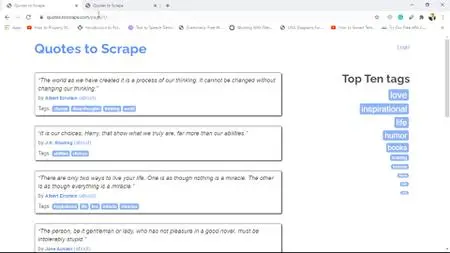
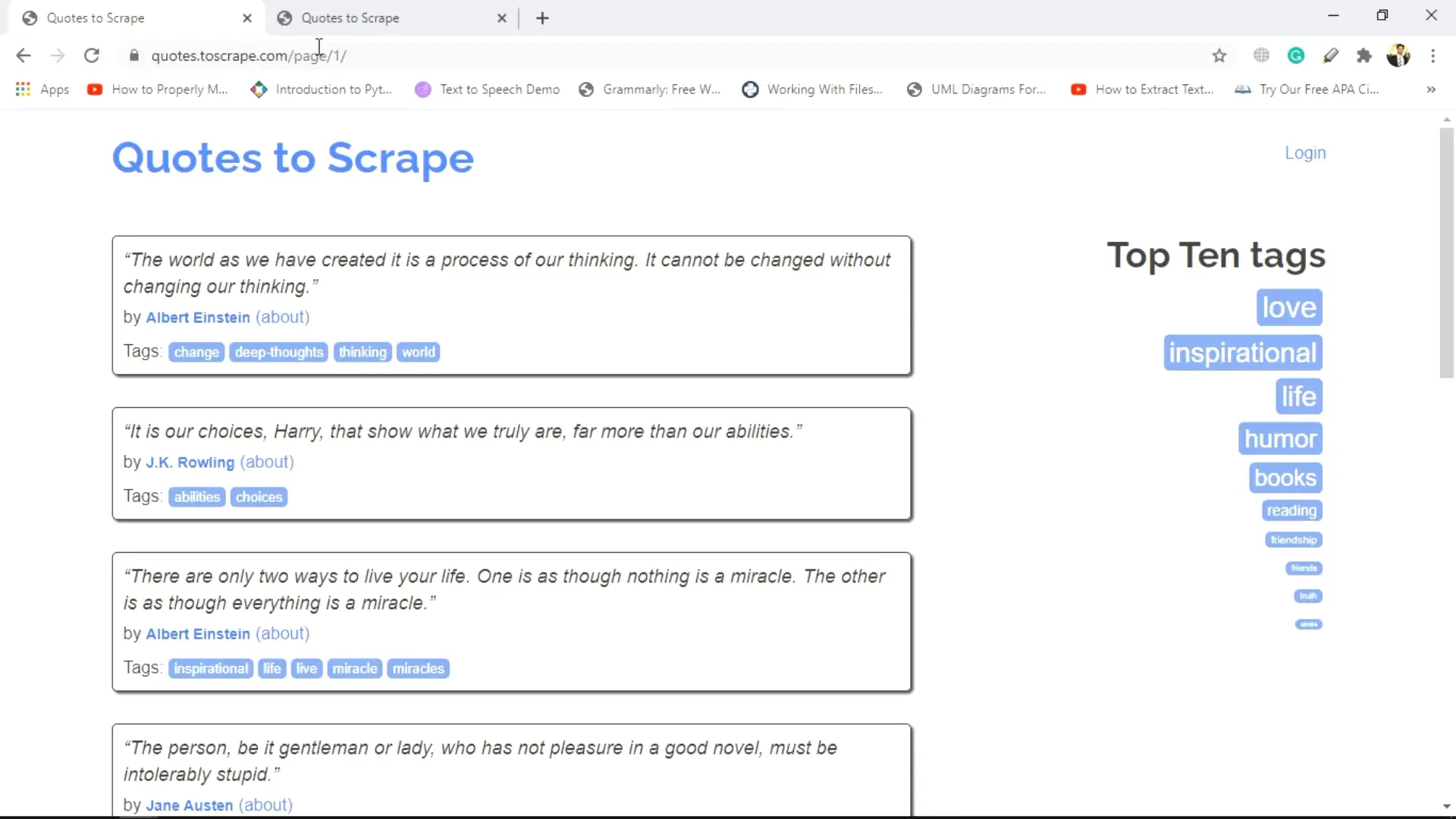
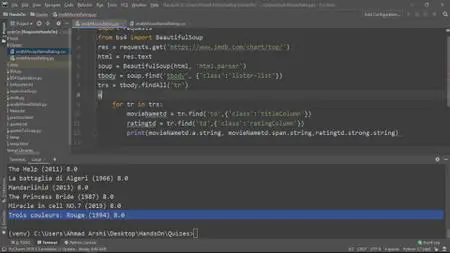
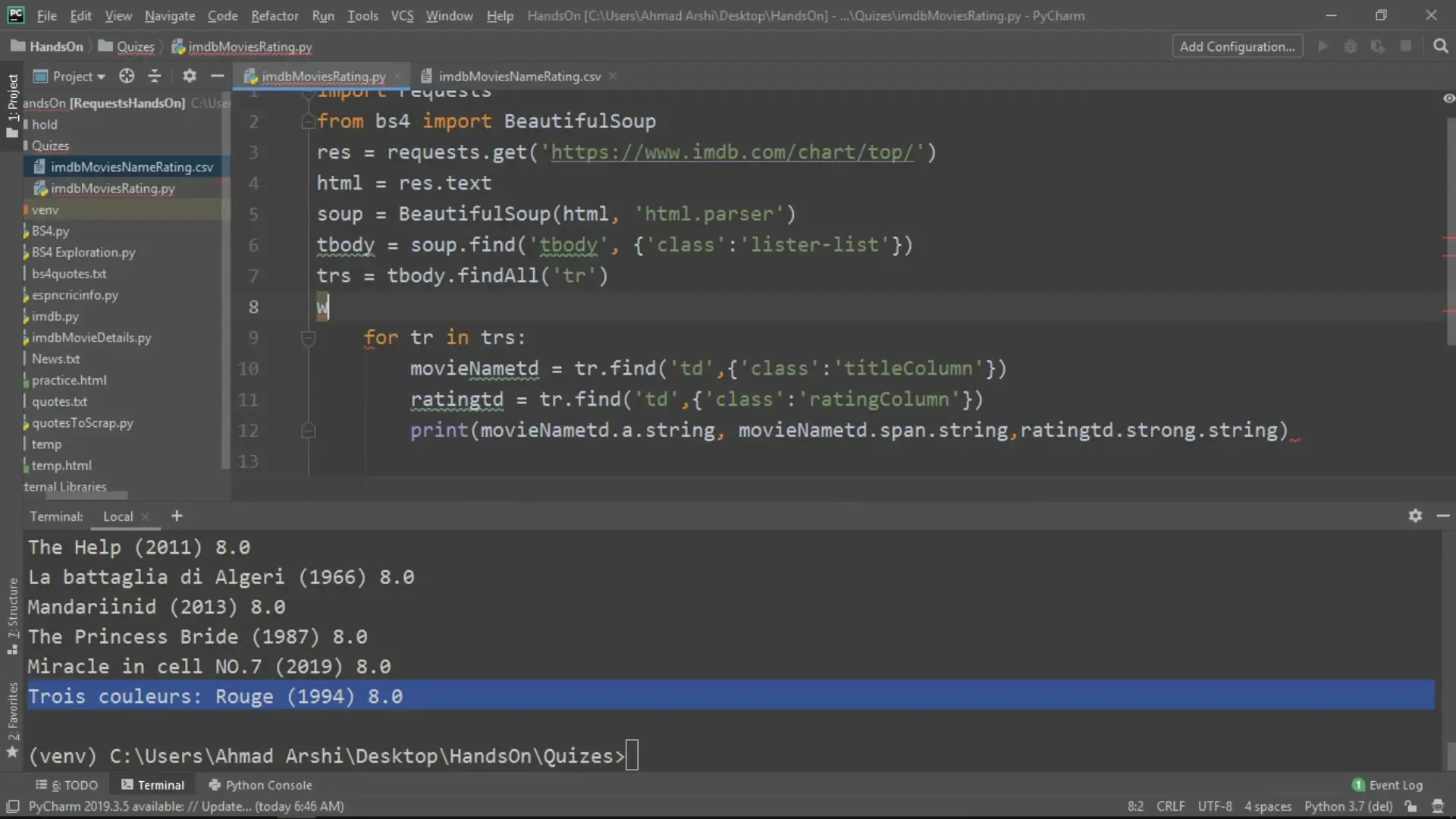
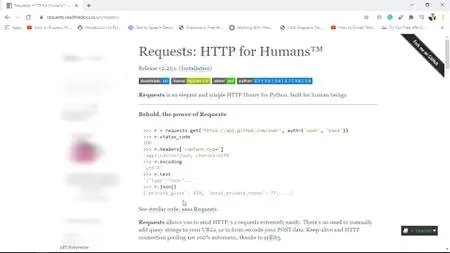
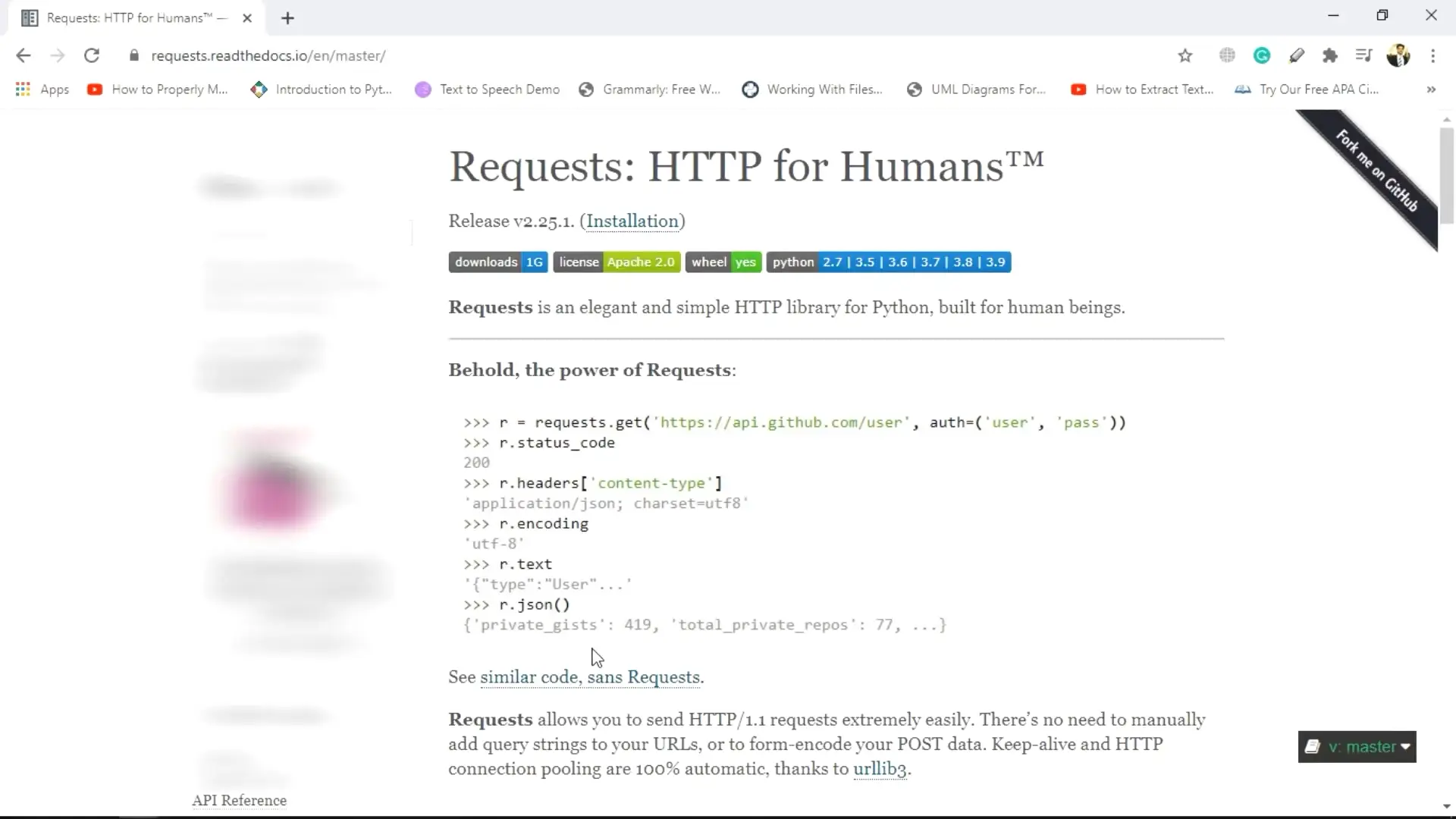
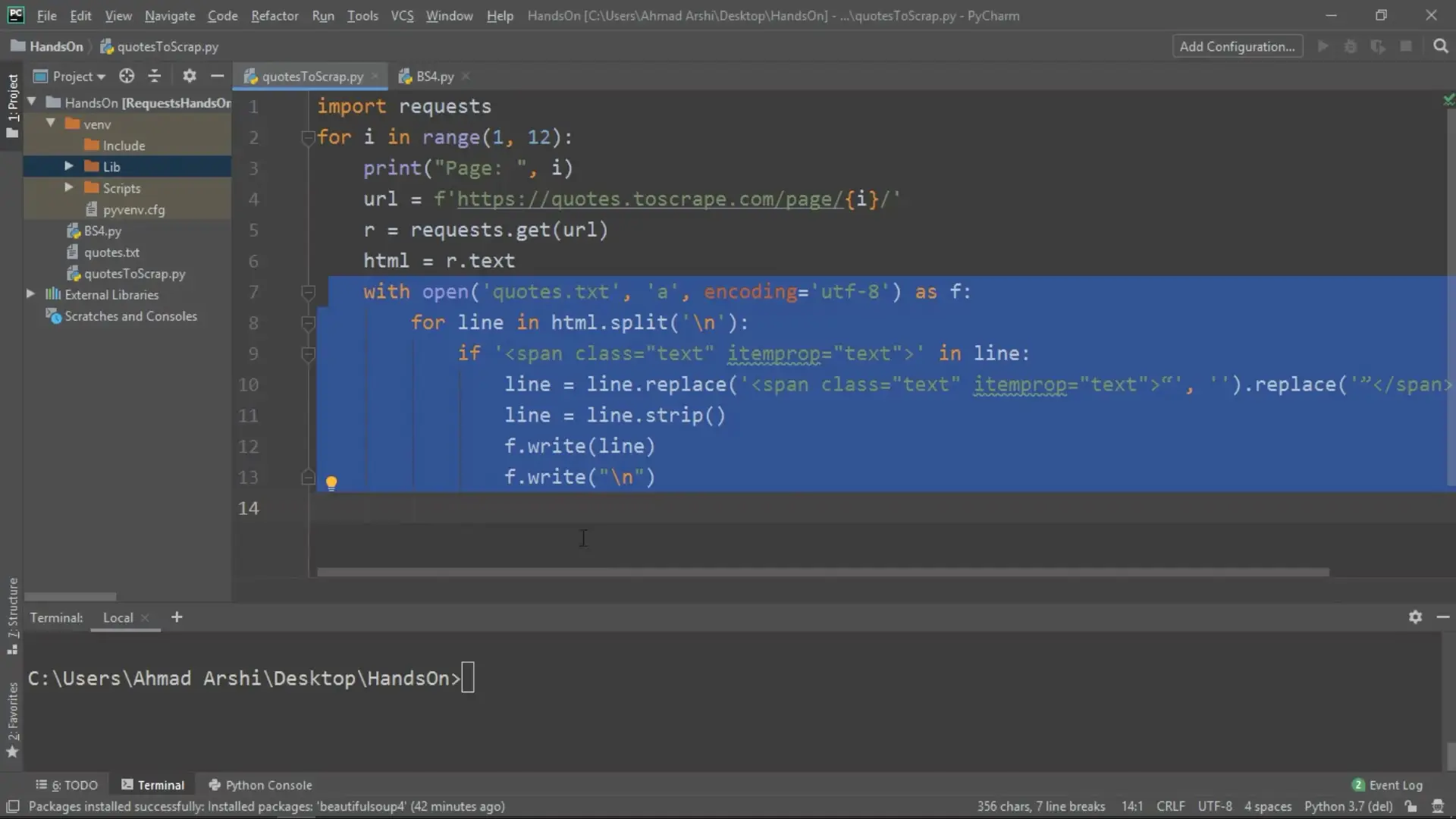
Part 3 is all about data scraping and data mining. You will cover important concepts such as Internet Browser execution and communication with the server, synchronous and asynchronous, parsing data in response from the server, tools for data scraping, Python requests module, and more.
In Part 4, you will be using MongoDB to develop an understanding of the NoSQL databases. You will explore the basic operations and explore the MongoDB query, project and update operators. We will wind up this section with two projects: Developing a CRUD-based application using Django and MongoDB and implementing an ETL pipeline using PySpark to dump the data in MongoDB.
By the end of this course, you will be able to relate the concepts and practical aspects of learned technologies with real-world problems.
All the resources of this course are available at https://github.com/PacktPublishing/50-Hours-of-Big-Data-PySpark-AWS-Scala-and-Scraping